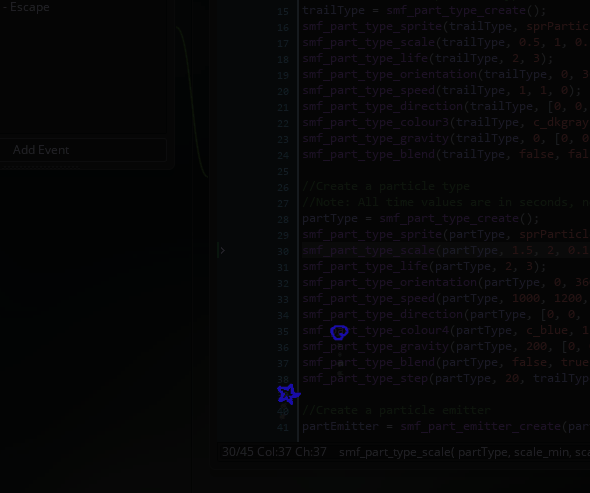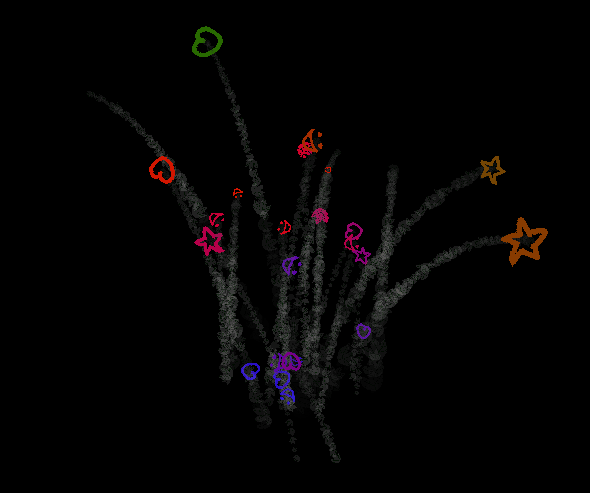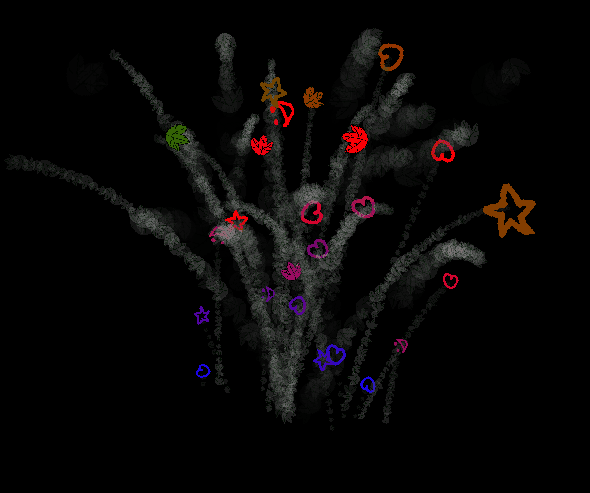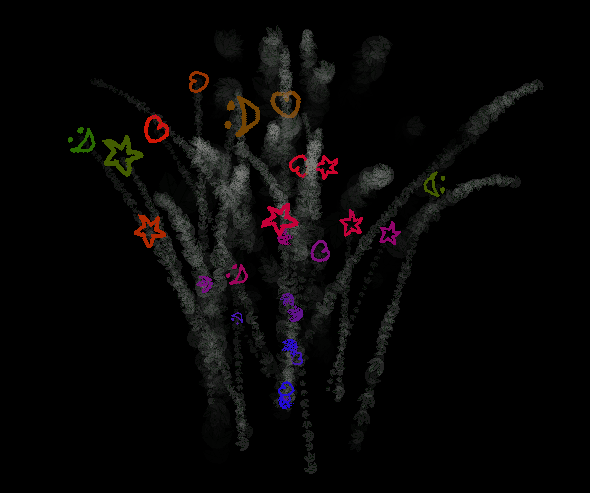
Because of the limited uniforms, I've opted to resubmitting the vertex buffer for each emitter. I've made a logging system for keeping track of previous positions of moving buffers, but this only supports changes to the coordinates - meaning that if the emitter changes orientation, all the particles that have already been spawned also change the orientation of their starting positions, which in turn affects their current positions. This is visible in the cube emitter GIF I posted up there, notice how the trail of smoke looks like it's rotating along with the cube! So it is in fact an artifact, but in my opinion it's an acceptable artifact, at least in some cases.
So yes, indeed, the particles are completely deterministic, decided only by the emitter's time alive and the index of the particle, which is set in the vertex buffer. Their positions are calculated like this:
Also, the vertex buffer is cut down to the absolute minimum:
So yes, indeed, the particles are completely deterministic, decided only by the emitter's time alive and the index of the particle, which is set in the vertex buffer. Their positions are calculated like this:
Code:
vec3 startPos = u_emitterPos[emitterInd].xyz;
float startScale = mix(u_partScale[0], u_partScale[1], gold_noise(partStartTime));
float startSpeed = mix(u_partSpeed[0], u_partSpeed[1], gold_noise(partStartTime));
float startAngle = mix(u_partAngle[0], u_partAngle[1], gold_noise(partStartTime));
vec3 currentPos = startPos;
currentPos += startDir * (startSpeed * partTimeAlive + u_partSpeed[2] * partTimeAlive * partTimeAlive); //Speed
currentPos += u_partGravAmount * u_partGravVec * partTimeAlive * partTimeAlive; //Gravity
float currentScale = startScale * (1.0 + partTimeAlive * partTimeAlive * u_partScale[2]);
float currentAngle = startAngle + partTimeAlive * u_partAngle[2];
Code:
var mBuff = buffer_create(partSystem[| SMF_partSys.ParticlesPerBatch] * 12, buffer_fixed, 1);
for (i = 0; i < partSystem[| SMF_partSys.ParticlesPerBatch]; i ++)
{
for (var j = 0; j < 3; j ++)
{
buffer_write(mBuff, buffer_u8, i mod 256);
buffer_write(mBuff, buffer_u8, i div 256);
buffer_write(mBuff, buffer_u8, i div (256 * 256));
buffer_write(mBuff, buffer_u8, j);
}
}